https://itnan.ru/post.php?c=1&p=577404

Рабочее место
Это устройство размещается непосредственно в рабочей зоне на складе запасных частей. Чем больше диапазон дистанций для размещения этого устройства, тем лучше. Оптимальное соотношение цена-качество-дистанция у такого кронштейна NB North Bayou Gaming Monitor Stand NB45-B.
Цикл статей
После публикации статьи Использование OpenCPN для автоматизации производства / Хабр (habr.com) в личной почте были вопросы по настройке программного обеспечения на собранном устройстве.
В той статье были даны ключевые ссылки на рабочий в плане TS, LCD и emmc (тачпанели, экрана и встроенной памяти) имидж Debian Linux. И ссылки на строчки открытого кода, которые достаточны для опытного специалиста с избытком времени на изучение чужого кода.
Там же подробно было показан один из возможных способов механической сборки компонентов OLIMEX LTD – OLinuXino Arduino Maple Pinguino ARM Open Source Hardware Development Boards. Все компоненты этой компании идут с подробным открытым описанием как необходимого программного обеспечения, так и с полной открытой публикацией всего дизайна железа. То есть любой желающий может разработать, изготовить и заказать на любом заводе свою собственную интегрированную плату взяв за основу разведенные платы Olimex.
В этой статье будут более детально и последовательно приведены все необходимые конфигурации как самого имиджа Linux, так и необходимых библиотек для OpenCPN и для новых плагинов, о которых я рассказывал в предыдущей статье.
Настройки имиджа Linux
Мы используем Olimexino-MICRO A20. На нашей плате есть память emmc и у нас уже подключён экран LCD через кабель IDC40. На сайте производителя есть кабели длинной 6 см, 10 см и 15 см. Они стоят не дорого и можно купить сразу 3 кабеля и по месту подобрать тот который вам подходит. Либо попробовать использовать кабель от старых настольных PC, которым подключались жесткие диски до эпохи SATA.
Для активизации LCD мы идем с правами root в каталог /root. Пароли по умолчанию в имидже Olimex Debian Linux – olimex. Изначально настроены два пользователя – root и olimex. Оба с одинаковым паролем – olimex. В каталоге мы запускаем скрипт настройки LCD, который открывает меню, где и можно выбрать тип вашего LCD.
./change_display.shЯ предпочёл вначале сделать все предварительные настройки на SD карте, с целью сохранения загрузочного имиджа на всякий случай. Но вы можете на этом этапе перейти на работу со встроенной emmc памяти.
./emmc.shРасширять полученную рабочую партицию мне не пришлось, скрипт все делает автоматически. Дождавшись завершения работы скрипта, можно выключить питание устройства.
poweroffВытащить SD карту и путем нажатия кнопки ресет либо путём включения и выключения штекера питания включить устройство. Примерно через 30 секунд загрузка должна завершится и вы увидите X десктоп на своей LCD панели. Если вам необходимы манипуляции с загрузчиком и вы хотите видеть процесс загрузки ядра, подключите до включения устройства дополнительный HDMI монитор.
Библиотеки необходимые для OpenCPN 4.0
Для надежности и для компиляции собственных модулей лучше всего клонировать репозиторий OpenCPN.
git clone https://github.com/OpenCPN/OpenCPNДля нашей версии ядра крайняя версия OpenCPN, которая собирается без проблем это 4.1, но мы будем использовать версию 4.0.
cd OpenCPN
git checkout v4.0.0Для компиляции OpenCPN нам нужны следующие библиотеки и пакеты
По сути в списке достаточно оставить только одноименные пакеты с суффиксом -dev, так как сами библиотеки поставятся автоматически, но я привет те команды, которые я использовал.
sudo apt-get install cmake build-essential libwxbase3.0-0 libwxbase3.0-dev sudo apt-get install libwxgtk3.0-dev libwxgtk3.0 sudo apt-get install libcairo2-dev libcairo2 sudo apt-get install portaudio19-dev sudo apt-get install curl-dev curl libcurl libcurl4-openssl-dev sudo apt-get install libpangocairo-1.0-0 libpango libpango1.0-dev sudo apt-get install libsdl-pango-dev pkg-config sudo apt-get install libpangomm-1.4-dev libpangox-1.0-dev sudo apt-get install libgtk-pixbuf2.0-0 libgtk-pixbuf libgtkpixbuf sudo apt-get install libgtkextra-dev libgtk-3.0 libgtk3.0-cil-dev sudo apt-get install liblzma-dev libarchive-dev libzip2 lbzip2 libbz2-dev sudo apt-get install libexif-dev libexif-gtk-dev libelf-dev sudo apt-get install gettext libtinyxml2-dev
Не все эти библиотеки нужны, кой-где возможны ошибки в написании. Но с помощью следующей команды можно найти правильное название.
sudo apt-cache search libtinyxДополнительные библиотеки
Пару библиотек для этого проекта я собрал самостоятельно. Стоковая версия OpenCPN не подключается к базе данных MySQL, поэтому потребовались эти доработки. Склонировал automake-1.9 и mysqlcppapi-2.0.0. При сборке последней пришлось поправить пару строчек в 1-ом или 2-ух файлах исходного кода, так как мы по умолчанию используем старый компилятор.
При желании можно собрать и свою версию libwxgtk3.0. Я это сделал, чтоб убедится что все зависимости установлены.
В старой версии OpenCPN работа с прогнозами погоды была не такая продвинутая как в zygrib_7. Поэтому можно собрать и использовать дополнительную программу, а можно доработать встроенный плагин OpenCPN для разбора файлов прогноза. В итоге у вас из исходников должно получиться 2 deb пакета:
zygrib-maps_7.0.0-1_all.deb
zygrib_7.0.0-1_armhf.deb
Библиотеки необходимые для подключения принтера этикеток Zebra GK420d
После установки следующих библиотек и настройки cups Zebra GK420d cтал печатать без доработки исходного кода. При не правильной настройке драйвера или размера этикетки принтер сообщает об ошибке превышения отступов.
sudo apt-get install cups foomatic-db-compressed-ppds cups-pdf smbclient xpp
sudo apt-get install ghostscript-x printer-driver-gutenprint
sudo apt-get install cups-browsed font-droid libpaper-utilsВ wxWidget в библиотеке печати прошито намертво приложение evince с характерными для него ключами. Эта команда хранит свои параметры в бинарном формате в каталоге:
/home/olimex/.local/share/gvfs-metadata
Это стандартное хранилище для gnome, но не для нашего облегчённого оконного менеджера – lxde.
Автостарт в lxde
Кстати, если вам нужно настроить автостарт для этой среды, нужно редактировать этот файл:
/home/olimex/.config/lxsession/LXDE/autostart
Либо скопировать desktop файл из каталога /usr/share/application/ в каталог, как в примере ниже:
/home/olimex/.config/autostart/LXinput-setup.desktop
Настройка lp
Я использовал для распечатки команду lp, которую можно настроить на заданный тип принтера из командной строки. Более подробную информацию смотрите на вашем локальном web CUPS сервере через Mozilla Firefox: http://localhost:631/help/options.html
Там же через web интерфейс можно выбрать доступный принтер, настроить драйвера для притера (ppd файлы), поменять права доступа к нему. Так же можно посмотреть очередь печати и возможные ошибки возвращаемые принтером.
lpstat -p -d
lpoptions -d Zebra_Technologies_ZTC_GK420d
lp testprint.pdf
lp test.txt
lp test.jpgДля запуска нужного приложения по нажатию кнопки “Print preview” в wxWidget нужно обновить альтернативные программы. По умолчанию для показа перед печатью используется браузер, но только если не установлен gv или xpdf, а так же evince.
После того как вы установите необходимый просмотрщик файлов можно попробовать использовать команды:
xdg-mime default lp.desktop application/pdf
update-alternatives --config x-www-browserИ изменить содержание файла /home/olimex/.config/mimeapps.list
application/pdf=pdf.desktopна
application/pdf=lp.desktopФайл /usr/share/application/lp.desktop получается копированием файла xpdf.desktop путём замены строчки на Exec=lp. Параметр имя в этом файле тоже надо поменять: Name=lp
Изменить файл /etc/papersize следующим содержанием:
w288h432Настройка WiFi
Лучше всего подходит модуль R5370-ANT. Он имеет антенну и поддерживает все необходимые протоколы и самое главное поддерживается этим имиджем Olimex из коробки. Имеется аналог, но без антенны R5370.
sudo apt-get install wpasupplicant
rfkill list
rfkill unblock wifi
iwconfig
sudo ifconfig wlan0 up
sudo iwlist wlan0 scan | grep ESSIDВ файл /etc/network/interfaces добавить:
auto wlan0
iface wlan0 inet dhcp
wpa-ssid your_wifi_ssid
wpa-psk your_wifi_passssid и psk значения в этих файлах и командах надо заменить на принятые в вашей сети. Для генерации файла /etc/network/wpa_supplicant.conf
cd /etc/network
wpa_passphrase your_wifi_ssid your_wifi_pass | sudo tee wpa_supplicant.confФайл получиться примерно такой
network={
ssid=your_wifi_ssid
scan_ssid=1
psk=your_wifi_pass
key_mgmt=WPA_PSK
}Следующая команда выполнит подключение устройство к местной wifi сети:
cp wpa_supplicant.conf /etc/wpa_supplicant.conf
killall wpa_supplicant
sudo wpa_supplicant -c /etc/wpa_supplicant.conf -i wlan0
iwconfig
dhclient wlan0
ifconfigПосле рестарта устройства WiFi подхватится автоматически.
Настройка времени
apt-get install ntp
timedatectl status
timedatectl list-timezones
timedatectl set-timezone Europe/MadridИзменение драйвера Zebra GK420d
Новые принтеры Zebra GK420d отличаются процедурой инициализации для USB от выпущеных ранее 2007 года. Возможно придется внести изменения в настройки CUPS (ELP II) или в ppd файли или в исходный код.
Настройки могут быть связаны с отступами, шириной распечатываемой области (Print Width – на фото ниже помечен овалом справа). Zebra использует старый язык управления принтерами подобный ELP и при переходе к новым стандартам растровой печати с поворотом страницы требуется компенсатция левого отступа.
Вот примерно в этом месте можно вставить изменения прямо в исходники CUPS. Но лучше исправить ppd файл и подгрузить параметры стандартным образом.
Для распечатки конфигурации принтера нажмите кнопку на панели принтера и не отпускайте до момента пока светодиод мигнёт один раз, затем отпустите кнопку.
")
Серия из одного и двух миганий (пока вы держите кнопку нажатой и отпускаете после двойного мигания) обеспечит автоматическую калибровку носителей (параметры на фото помечены прямоугольником слева). Будут выплюнуты от одно до четырёх наклеек, которые можно будет руками венуть назад.
Если удерживать кнопку до последовательной серии в пять миганий (одно, два, три, четыре, пять), то будет начата распечатка прямоугольников с шагом в 4 мм. Повторное нажатие кнопки подтвердит выбранную вами ширину.
Процедура инициализации новых принтеров выпущенных в 2021 году или позже:
~SD15
~TA000
~JSN
^XA
^ST09,15,2021,11,06,15,M
^XZ
^XA
^SZ2
^PW812
^LL1218
^PON
^PR5,5
^PMN
^MNY
^LS0
^MTD
^MMT,N
^MPE
^XZ
^XA^JUS^XZ~SD10 – яркость
~TA000 – без отрывания этикетки (для этого надо подключить резак)
~JSN – обратная подача по умолчанию (нет)
^SZ2 – режим EPL II
^PW609 – ширина принтера
^LL1246 – длинна этикетки
^PR5,5 – скорость вывода на печать
^MNY – отслеживание подложки между этикетками, ^MNA – автоматическая калибровка, ^MNM – отлеживание чёрных полосок, ^MNN – рулон без перерывов
^LS0 – левое положение (отступ)
^XA – запуск команды форматирования
^JUS – команда сохранения конфигурации
^XZ – завершение команды форматирования
Для отключения сенсора новой этикетки, если вы просто хотите распечатывать чеки, используют следующую команду:
^XA^MNN^JUS^XZПошлите эту команду в принтер или вставте ^MNN - рулон без перерывов в поток данных, который посылаете.
Пример распечатки документа в wxWidget. Пример настройки причуды для принтера в файле /usr/share/cups/usb.
Wouldn’t it be needed to add this quirck to org.cups.usb-quirks ?
# Zebra GD420 (https://github.com/apple/cups/issues/5395)
0x0a5f 0x0080 unidir no-reattachКалибровка Тачпанели
Как упоминалось ранее было использовано следующее ультрaзвуковое устройство LCD-TS15.6. Лучшая инструкция по конфигурации и калибровке тут. Но 7 шаг из этой инструкции делать не обязательно, и скорее это приведет к постоянной перегрузке устройства.
Есть лог настройки, который реально помогает понять что нужно сделать.
После установки тачпанели в устройство нам надо повторить выполнение двух команд.
ts_calibrateПосле запуска этой команды нужно будет последовательно нажать на 5 крестиков на экране. 4 по краям и один в центре. Затем скопировать записанные данные в надлежащее место.
cp /etc/pointercal /usr/etc/pointercalНеобходимо перегрузить систему. Затем убедится что USB интерфейс тачпанели имеет адрес, который прописан в /usr/share/X11/xorg.conf.d/20-ts.conf и в /etc/environment. Для уверенности я просто отключаю на USB хабе все остальные устройства и включаю их после загрузки системы.
Компиляция OpenCPN
Перед началом компиляции убедитесь что системные часы установлены на текущую дату и время. Без этого шага из-за неправильной автоматической настройки даты модификации файлов, утилита make будет каждый раз перекомпилировать все файлы и сообщать об возможной ошибке. Это очень затратно по времени. Полная компиляция OpenCPN на данном железе A20 может длиться дольше 40 минут.
date -s "16 AUG 2021 14:57"
cd OpenCPN
mkdir build
cd build
cmake ../
make
su
make installЗапуск OpenCPN
opencpn -no_openglOpenGL это конечно боль этого старого имиджа Debian для SoC A20. Полагаю что в имиджах для новых продуктах Olimex решат проблему и по умолчанию настроят драйвера и поставят необходимые библиотеки для аппаратного ускорения графики.
Так как у нас на производстве используется планарный (не 3D) дизайн, то пока такой задачи как построение объемных 3D моделей не стоит, как и наложение слоёв в чертежах на данном рабочем месте. Возможно в будущем это будет актуально для других рабочих мест.
Отступление про весы

В прошлой статье не хватило места рассказать про подключение данных весов к USB разъёму. На выходе этих весов обычный COM DB-9, каких уже нет на современных компьютерах.

Для быстрого превращения COM в USB без паяльника я использовал MOD-RS232 и USB-SERIAL-F. С этими кабелями я много работал прошивая ESP8266 поэтому был совершенно уверен, что они совместимы с любой версией Linux без компиляции дополнительных модулей.
Я открутил разъем от корпуса, подключил модули внутри корпуса, выпустив USB конец кабеля наружу. И предварительно закрепив узел кабеля внутри весов.
Включил режим непрерывной передачи параметров и стал регулярно через MiniCOM принимать данные в текстовом виде от весов в момент изменения веса. Данные состояли из 3 параметров, которые дублировали содержимое 3 экранов на лицевой панели весов (Weight, Unit Weight, Total Count).
Причем меня интересует только Weight, потому что Unit Weight удобнее брать из Базы данных ERP. А Total Count вычислять самостоятельно и сравнивать с необходимым по заказу. И соответственно выводить Диалог с Progress Bar. Тогда работнику не нужно будет следить за числами, достаточно просто смотреть на индикатор.
Создание виртуальных весов для отладки
Так как наши весы заняты на производстве, то первым делом я добавил в подходяшее место в OpenCPN симуляцию посылки весами данных. Это можно считать своеобразным тестом будущего парсера протокола весов.
void PlugInManager::SendNMEASentenceToAllPlugIns(const wxString &sentence)
{
wxString sentence1 = "G.W. :+ 10.1155kg\n";
// wxString sentence1 = "U.W. :+ 0.08155 g/pcs\n";
// wxString sentence1 = "Total:+ 144 pcs\n";
wxString decouple_sentence(sentence1); // decouples 'const wxString &' and 'wxString &' to keep bin compat for plugins
for(unsigned int i = 0 ; i < plugin_array.GetCount() ; i++)
{
PlugInContainer *pic = plugin_array.Item(i);
pic->m_pplugin->SetSentence(decouple_sentence);
if(pic->m_bEnabled && pic->m_bInitState)
{
if(pic->m_cap_flag & WANTS_NMEA_SENTENCES)
pic->m_pplugin->SetNMEASentence(decouple_sentence);
}
}
}Как видно в коде выше OpenCPN формирует строку для передачи в плагин NMEA. По началу я создал отдельную библиотеку для протокола весов. Но в силу нехватки времени переключился на реализацию протокола весов прямо внутри библиотеки разбора NMEA. При этом я планирую вынести весь этот код в отдельную библиотеку дашборда в будущем во время рефакторинга.
Для того чтоб срабатывало прерывание и вызывалась эта функция, я подключал мой USB GPS приёмник. Благодаря этой дополнительной строчке я получал данные характерные для весов.
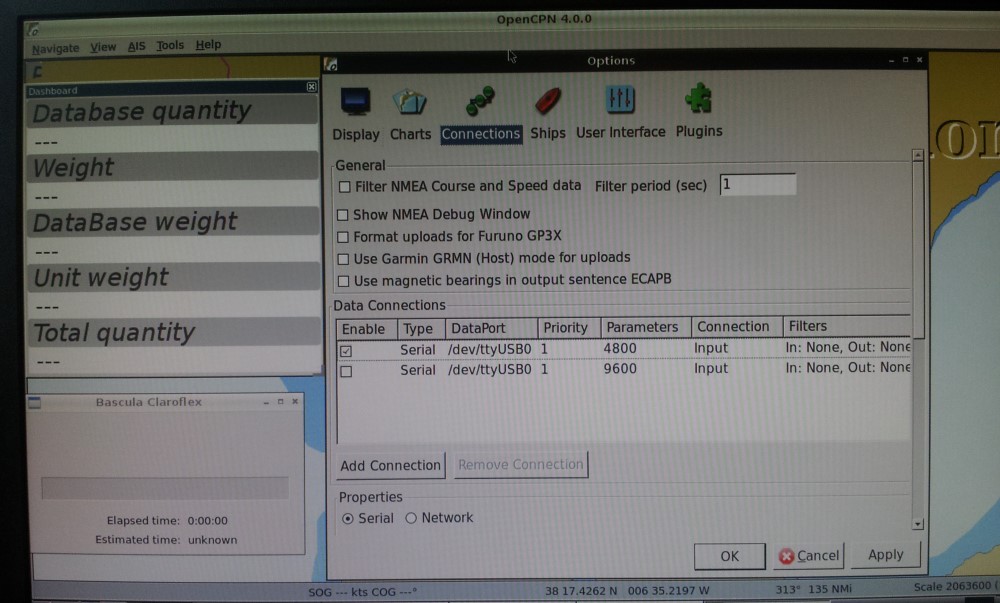
Для получения реальных данных с весов надо подключить весы, сменить в графических настройках OpenCPN источник данных с GPS на MyWeigh, закомментировать эту тестовую строчку и перекомпилировать этот файл с последующей линковкой и установкой исполняемых библиотек и самой программы opencpn.

Плагин
Функция SetSentence добалвлена в плагин dashboard_pi по аналогии с SetNMEASentence. Причем все протоколы вынесены в отдельные подкаталоги этого плагина и оформлены в виде классов. Я поступил точно так же и завел подкаталог myweigh, в котором находятся все необходимые файлы для парсинга протокола весов.
При компиляции и линковке возникли ошибки. Как я сейчас понимаю, скорее всего из-за не прописанного myweigh.h или myweigh.hpp. Все эти исправления я оставил на рефакторинг, а сами файлы перенес в основную часть плагина dashboard_pi. То есть на один уровень выше, не выделяя в подкаталог.
Посмотрим на функцию АPI плагина, которую я добавил.
void dashboard_pi::SetSentence( wxString &sentence )
{
// m_MyWeigh << sentence;
m_NMEA0183 << sentence;
// wxCharBuffer buf = sentence.ToUTF8();
// wxString mnemonic = buf+1;
// mnemonic = mnemonic+2;
bool bGoodData = false;
if( m_NMEA0183.PreParse1() )
{
if( m_NMEA0183.LastSentenceIDReceived == _T("G.W."))
{
if( m_NMEA0183.Parse1() )
{
bascula_weigh = 0.0;
if(m_NMEA0183.Gw.IsDataValid == NTrue)
{
bascula_weigh = m_NMEA0183.Gw.UnitWeighKg;
bGoodData = true;
SendSentenceToAllInstruments( OCPN_DBP_WEIGH, bascula_weigh, "kg" );
// wxString msg1;
// msg1 += _T("\n\n");
progress_dialog = instrument_progress_dialog->GetPprog(bascula_weigh, db_weigh, db_quantity);
// progress_dialog->Hide();
// instrument_progress_dialog->ppprog->Update(20);
// instrument_progress_dialog->ppprog->Show();
// instrument_progress_dialog->ppprog->Raise();
}
}
}
if( m_NMEA0183.LastSentenceIDReceived == _T("U.W."))
{
if( m_NMEA0183.Parse1() )
{
double unit_weigh = 0.0;
if(m_NMEA0183.Uw.IsDataValid == NTrue)
{
unit_weigh = m_NMEA0183.Uw.UnitWeighKg;
SendSentenceToAllInstruments( OCPN_DBP_UNIT_WEIGH, unit_weigh, "kg/pcs" );
}
}
}
if( m_NMEA0183.LastSentenceIDReceived == _T("Tota"))
{
if( m_NMEA0183.Parse1() )
{
double total_unit = 0;
if(m_NMEA0183.Tot.IsDataValid == NTrue)
{
total_unit = m_NMEA0183.Tot.TotalUnit;
// getUsrDistanceUnit_Plugin( g_iDashDepthUnit );
SendSentenceToAllInstruments( OCPN_DBP_TOTAL_QUANTITY, total_unit, "pcs" );
// SendSentenceToAllInstruments( OCPN_DBP_TOTAL_QUANTITY, total_unit, m_NMEA0183.LastSentenceIDReceived );
}
}
}
}
// if(bGoodData)
// {
// Refresh(false);
// }
}
В 13, 35, 48 строчке видно что парсинг происходит по первым 4 символам принимаемым от весов. В отличие от NMEA протокола нет пропуска первого служебного символа. Так как протокол весов не содержит такового.
После 2 дополнительных проверок m_NMEA0183.Parse1() и m_NMEA0183.Gw.IsDataValid происходит присваивание значения через вызов метода соответствующего класса (Weight, Unit Weight, Total Count).
В строчках 20, 42 и 55 происходит вызов 3 различных классов, которые написаны для разбора 3 различных сообщений весов. Эти классы мы посмотрим позже (Смотрите параграф ниже – “Класс Gw”).
А пока обратим внимание на вызов функции в 22 строчке:
SendSentenceToAllInstruments( OCPN_DBP_WEIGH, bascula_weigh, "kg" ); Тут происходит выбор виртуального дисплея или инструмента (яхтенный сленг) для вывода полученных данных – bascula_weigh. Причем указываются единицы измерения килограммы – “kg”. Отображение информации происходит в момент её получения.
Все задержки связаны только с работой нашего устройства и физических протоколов передачи через COM->USB. И не зависят от Бакенд сервера. Поэтому можно считать что мы на своём дашборде контролируем и получаем информацию в реальном режиме времени. Так как на нашем заводе не будет более 10 таких устройств (на текущий момент всего 2 устройства), то бакенд для доступа к базе данных не нужен. Можно забирать необходимые данные напрямую.
Реализацию класса DashboardInstrument_Weight я сделал по аналогии с уже готовым стандартным одиночным (одно значение) инструментом. Посмотреть его можно в файле instrument.cpp.
Разбор протокола весов
Заглянем в файл sentence.cpp. Разница в методах Field1 и Field заключена всего в одной строчке которая определяет первый разбираемый символ и выборе другого разделяющего символа. Это 8 строчка, которая говорит что мы считаем символы с нулевой позиции (в Си и С++ индексы нумеруются с 0).
onst wxString& SENTENCE::Field1( int desired_field_number ) const
{
// ASSERT_VALID( this );
static wxString return_string;
return_string.Empty();
int index = 0; // Keep over the G/U at the begining of the sentence
int current_field_number = 0;
int string_length = 0;
string_length = Sentence.Len();
while( current_field_number < desired_field_number && index < string_length )
{
if ( Sentence[ index ] == ' ' )
{
current_field_number++;
}
if( Sentence[ index ] == '+')
return_string += Sentence[ index ];
index++;
}
if ( current_field_number == desired_field_number )
{
while( index < string_length &&
// Sentence[ index ] != '+' &&
Sentence[ index ] != ' ' &&
// Sentence[ index ] != ',' &&
Sentence[ index ] != '+' &&
Sentence[ index ] != 0x00 )
{
return_string += Sentence[ index ];
index++;
}
}
return( return_string );
}
А еще мы запятую ‘,’ заменили на пробел ‘ ‘, а звездочку ‘*’ на плюс ‘+’ в полном соответствии с протоколом весов.
Класс Gw
Вызов этого парсинга происходит через функцию Double1 из нашего класса Gw.
bool GW::Parse( const SENTENCE& sentence )
{
/*
UW - Unit Waigh
1 2 3 4 5
| | | | |
$--VLW,x.x,N,x.x,N*hh<CR><LF>
Field Number:
1) Total cumulative distance
2) N = Nautical Miles
3) Distance since Reset
4) N = Nautical Miles
5) Checksum
*/
/*
** First we check the checksum...
*/
// if ( sentence.IsChecksumBad( 5 ) == TRUE )
// {
// SetErrorMessage( _T("Invalid Checksum") );
// return( FALSE );
// }
// TotalMileage = sentence.Double( 1 );
UnitWeighKg = sentence.Double1( 2 );
// UnitWeighKg = 20.0;
// TripMileage = sentence.Double( 3 );
return( TRUE );
}Как видно все комментарии требуют рефакторинга, который я планировал сделать после подключения другого вида весов, чтоб уловить общие закономерности в китайских протоколах и сделать этот метод разбора более гибким. То есть добавить дополнительные проверки и условия.
Прогрес диалог
Среди инструментов создан еще один класс DashboardInstrument_ProgressDialog который предназначен для вывода модального окна с индикатором веса (аналогичного индикатору копирования файлов). Оно всегда висит сверху и не закрывается даже при закрытии родительского окна.
Идея в том что когда работник из пакета насыпает мелкие детальки на весы, ему не нужно их считать и не нужно нажимать дополнительные кнопки на весах для каждой новой позиции в заказе. Кроме того система учитывает размеры полных пакетов и даёт информацию по остатку неполного пакета, который проходит через весы. Тем самым сокращается время на рутинные операции.
Формула расчета положение индикатора находится в файле instrument.cpp.
wxProgressDialog* DashboardInstrument::GetPprog( double bascula_weigh, double db_weigh, double db_quantity )
{
int cur_count;
cur_count = wxRound( pd_count * bascula_weigh / (db_weigh * db_quantity) );
if (cur_count > 90) { cur_count = 95; }
wxString msg5;
msg5.Printf(_T("%d * %d / ( db_weigh * db_quantity ) = %d "),
pd_count, wxRound(bascula_weigh), wxRound(db_weigh * db_quantity));
ppprog->Update(cur_count, msg5);
return ppprog;
}Индикатор доходит до 95% только, потому что после 100% он исчезает, где исправить это поведение я не знаю. Нужно чтоб этот диалог всегда находился на своём месте. Перерисовывать его каждый раз при выборе новой позиции считаю не рациональным по затратам времени.
Так же распечатывает необходимые этикетки. И делает это все в базе данных в рабочей ERP, состояние которой видит весь офис и может отслеживать выполнение заказа. Под офисом я понимаю отделы кладовщика, продажников, логистику, администратора и начальника.
Интерфейс пользователя
Весь новый интерфейс пользователя сосредоточен в отдельном втором основном модальном окне. Весь код которого находится в одном файле myframe1.cpp.
Доступ к базе данных оформлен внутри этого файла, но позже надо будет разделить и подумать чтоб в далёкой перспективе эту часть можно заменить на ORM или API.
Принтер управляется отдельными классами. Для построения списка распечатываемых этикеток и управления самим принтером есть специальные файлы: Label.cpp, LabelPoint.cpp, Select.cpp, labelprintout.cpp. В них все более или менее стандартно. Необходим опыт использования системы, чтоб понять в какую сторону двигаться.
В системе есть функции построения QR кодов (как растровых, так и текстовых), отрисовки изображения (как на экране, так и на этикетке).
Если будут интересны детали отрисовки окон с таблицами на wxWidget напишите в комментариях, тогда я дополню статью или напишу дополнительную по графическому интерфейсу пользователя, поведенческим вызовам или обработчикам мышки, клавиатуры, тачпанели.
Отступление про USB хаб
Чтоб подключить несколько устройств USB (тачпаннель, принтер, весы, wifi, bt для безпроводной клавиатуры и мышки) к OLinuxino A20 с всего лишь двумя USB разъёмами, нужно подключать USB hub. Но подобные хабы через один USB кабель при передаче данных могут обеспечить ограниченное питание на каждый порт\устройство.

Поэтому рядом с кабелем USB на них имеется специальный разъём для питания в 5 вольт всего мультиплексора. Сейчас такие блоки питания редкие.

Вероятно они использовались раньше для многих старых мобильных телефонов. Если вам не удастся подобрать штекер, то придется перепаивать на гнездо большего размера и дорабатывать корпус хаба под это гнездо.
Отступление про то в чём я мало разбираюсь
Есть вариант изготовления своей собственной платы периферии и стандартного модуля Olimex, подключаемого по шине расширения. В механическом плане это примерно плюс 5 мм -10 мм к толщине алюминиевого профиля необходимого для тачпанели и LCD (надеюсь что меня поправят опытные механики-электроники). Все конечно зависит от соединений плат внутри корпуса. Если взять с запасом на неудачные толстые кабели, то в целом 15 мм достаточно с запасом для интеграции всех готовых Olimex плат внутри металлического корпуса. Итого толщина профиля должна быть между 24 мм и 40 мм.
Примерно 30 лет назад, мы все в МИЭТ (год основания 1965) сдавали курсовик по начерталке на тему изготовления корпуса стандартного электронного устройства. Вероятно, технологии которые я использую для корпуса устройства, сопоставимы с возрастом моей новой яхты. East Anglian MkII изготовленной из дерева в Англии в 1961 году. Фотографии данного класса яхт есть в предыдущей стататье. Естественно у меня также имеются все оригинальные полные чертежи этой яхты, сделанной на заказ. Таким образом конструкция этой яхты, как и дизайн моего навигатора является Open-source hardware (OSH).

Уверен что в ближайшие годы Olimex найдет способ использовать микропроцессор с открытым дизайном, если такой появится на рынке. Существуют с 2000 года бесплатные программные продукты для дизайна микропроцессоров. Например, Static Free Software Home Page. В этом проекте мы с коллегами участвовали как русскоязычные тестеры и переводчики документации. И тогда веский аргумент о полной недоступности открытого во всех смыслах микропроцессора (включая устройство ядра) уйдет в прошлое. Предположительно говорю о ядре RISC-V. Наиболее вероятный чип для будущей платы Olimex на весну 2021 это Allwinner AP (application processor) SOC c открытм ISA (open standard instruction set architecture) для RISC-V. Вот тут подробнее. Оригинал статьи тут.
IMHO останутся вопросы по графическим сопроцессорам OpenGL, но со временем и их дизайн будет открыт.
Другие статьи на тему автоматизации яхтинга своими силами:
Использование OpenCPN для автоматизации производства / Хабр (habr.com)
IT техническая сторона яхтинга / Хабр (habr.com)
Шпаргалка, которая нужна на яхте / Хабр (habr.com)
IT Релокация на яхте. Из Швеции в Испанию / Хабр (habr.com)












Комментарии 20
ignat9920.01.2022 в 10:56
Традиционно гимн Си-шников.
Научно-технический рэп – Папа может в си – YouTube
AlexSelivanoff20.01.2022 в 16:12
Как начинающий пользователь яхты хочу спросить, в чем преимущество OpenCPN? В сравнении с навиониксом на планшете и стационарными картплоттерами типа всяких гарминов.
ignat9920.01.2022 в 17:18
Благодарю за вопрос.
Если бы вы посмотрели предыдущие статьи, то заметилибы что я воовсе не делаю программу навигации, я по совместительству автоматизирую производство на том что мне интересно.
Нам не нужен OpenGL. И у меня к нему в основном спортивный интерес.
Так же бы вы заметили что программа была использована на Olimex OlinuXino a20, потому что я это сделал ещё 5 лет назад и это было довольно экономное (25 евро) и производительное решение.
Сейчас меня привлекает эта система именно как пример использования wxWitgets вместе с Qt и особый фреймворк OpenCPN котороый подходит для задачь логирования и парсинга в реальном времени данных с UART (или COM портов попросому).
Короткий ответ – привлекает лицензией, скоростью, языком С, наличием плугинов и естественно полностью открытым кодом, который можно переделать например в спортивный автопилот или другие специфические задачи. Тоесть возможностью модификации кода под свои нужды.
AlexSelivanoff21.01.2022 в 14:58
Спасибо!
В целом понял, пойду другие статьи почитаю.
>> спортивный автопилот
А чем спортивные автопилоты отличаются от обычных круизёрских?
ignat9921.01.2022 в 15:07
Если предпочитаете в исходном коде то тут tactics_pi/src at master · bdbcat/tactics_pi (github.com)
Если с картинками Tactics [OpenCPN Manuals]
Если моими словами. То ветер меняется и волны меняются. А яхта в долгой гонке идёт сутками. Поэтому в каждой точке исходя из 2-х дневного прогноза можно определить несколько путей с примерно одинаковым временем. Но из за погоды, бывает важно пройти быстро или вообще не заходить в штилевую зону.
Так вот тактические дисплеи строят оптимальный теоретически предсказанный путь исходя из полученных свежих данных в режиме реального времени.
На коротких дистанциях для спортивных лодок важны только точные обновлённые карты, чтоб тупо в свежеобразовавшуюся помеху невьехать. Причем точность должна быть менее 5 метров, чтоб можно было вписаться в манёвр до помехи.
Для этого дисплеи ставят в кокпите. (Потому что пока бежишь от штурманского столика на пост, яхта может и 10 метров и даже несколько корпусов пройти при свежем ветре). Именно поэтому и возникла необходимость в Андроид устройстве, которое способно работать и с картами и с различными плугинами.
Круизёры при заходе в порт в очень свежий ветер. Когда надо обойти мели при входе, находятся практически в положении спортсменов. Надо расчитать маневр и пройти на безопасной глубине возле мели. Так как ветер часто наваливает яхту на мель.
Подробнее по ссылкам выше.
Про эпюры ещё забыл добавить. Яхты бывают разные. Некоторые лучше бакштагом идут, а некоторые под фордевинд заточены (дракары) или бейдевинд (мотосейлеры). Причём зависит и от поставленых парусов и от волнения. Все эти данные учитываются при прогнозе.
black_list_man20.01.2022 в 17:00
В свое время, будучи студентом очень сильно помучался в попытках собрать OpenCPN под андроид, и безуспешно. На одной из стадий была ошибка и я не знал как её решить. На, cruisersforum создал тему, и мне по этому поводу коротко ответили что мол версия для андроид более не бесплатная. Мне в общем то нужен был минимальный функционал (отображение карт s57, судна и ais целей) для научной лаборатории, где я тогда уже параллельно работал. При этом требовалась поддержка большого количества платформ, в том числе Android и желательно IOS. С этого момента началась моя эпопея с созданием собственного картографического движка. В качестве GUI выбор сразу пал на Qt. Сначала рендер карты осущетвлялся при помощи QPainter, затем полностью переделан под OpenGL (cовместимость с ES 2.0). Сейчас хочу и вовсе “оторвать” весь код от конкретного фреймворка (специфичные классы и методы) со всеми его лицензиями, чтобы для работы требовались лишь OpenGL контекст и ввод. Мне вообще кажется что OpenCPN довольно сильно устарел: wxWidgets с его лишь частичной кроссплатформенностью; первобытный fixed-pipeline OpenGL, чего только стоят glLineWidth и GL_LINE_STIPPLE.
ignat9920.01.2022 в 17:09
Благодарю за диалог.
В новой версии, поддержкой которой занимался человек, который удалил ключи автора из репозитария
Correct GL Vector symbol extents to allow cursor pick on entire rende… · OpenCPN/OpenCPN@b939f30 (github.com)
Он же отказывался отвечать на вопросы куда делся вот этот файл
https://github.com/bdbcat/wxWidgets/blob/master/include/wx/qt/private/wxQtGesture.h
Который тянет за тсобой wxGLCanvas для андроид.
Вообщем действительно собрать с ключём OpenGL версию OpenCPN под Android это проблема. Вот он практически отказался работать бесплатно. Идея была в том что все сами будут присылать автору деньги, но видимо она не сработала по причине что рынок очень узкий и мало людей ходят на яхте и ещё меньше используют OpenCPN.
Android version – segment violation · Issue #826 · OpenCPN/OpenCPN (github.com)
Android version – segment violation · Issue #826 · OpenCPN/OpenCPN (github.com)
If this is the most current version, I believe it should be wxWidgets 3.1.1 which is what the OS linux, windows and macos versrion 4.99 uses, otherwise if it is or Opencpn version 4.8.2 it should be wxWidgets 3.0.2 . You do not state which version you are trying to compile.
ignat9921.01.2022 в 13:15
Implement wxGestureEvent support for wxQt · wxWidgets/wxWidgets@a3d58da (github.com)
Вот тут обсуждение реализации wxQtGesture для Виндоус, тем самым человеком который убрал из Readme androidbuild информацию о том как ранее можно было зарегистрировать в Play Store приложение.
Кроме того все ветки и теги Android в официальном репозитории OpenCPN (начиная с первого Release android_v1.0.0 · OpenCPN/OpenCPN (github.com) ) строго для кода wx более позднего чем 3.0.0. Например можно попробовать использовать wxWidgets 3.0.2
Я же использовал другой репозитарий в этой статье bdbcat/wxWidgets: Cross-Platform GUI Library – Report issues here: http://trac.wxwidgets.org/ (github.com)
Основная проблема это изменение реализации wxGLCanvas. Так же подключения дополнительных возможностей вокруг шрифтов и настроек опций OpenGL.
ignat9920.01.2022 в 17:26
Qt это фреймворк кроссплатформенного софта. У него есть ГЮИ (GUI) – Qt Creatot
GUI в этом контексте это wxWidget
А рендер и фреймворк это OpenCPN (в котором уже есть конфигурация, списки объектов, принтера, модульная система драйверов сенсоров и дашборд через плагины).
Если вам нужен быстрый рендер, то почему не использовать что то типа CUDA? Или сразу Unity3D?
Вообщем вы определитесь с терминами. То что вы перешли на Qt связано с тем что все перешли с GTK+ туда после смены лицензии Qt около 2014 года?
black_list_man20.01.2022 в 19:23
Под GUI я имею в виду средство для создания кросплатформенного графического интерфейса. И в этом смылсе я противопостовляю wxWidgets – Qt. Понятно что Qt это больше чем просто GUI, но тем не менее это основная его задача – создание кросплатформенного софта с графическом интерфейсом.
Выбрал Qt в перую очредь из за большого количества поддерживаемых платформ и простоты сборки. Поменял таргет в среде(Qt Creator это все же просто среда разработки с точки зрения терминологии) c Windows на Android и вот ты уже собираешь проект под андроид или IOS. Без проблем. К тому же сам графический инфтефейс куда более кастомизируемый и визуально приятный. Особенно QML. wxWidgets в этом плане выглядит совсем уж аскетично.
CUDA же это про параллельные вычисления на картах NVIDIA а не про рендеринг, развне нет? Unity все-таки игровой движок, и скриптуется C# а не C++. Пришлось бы интегрировать С++ библиотеки (а большая часть библиотек из этой предметной области написана именно на C/C++ ). К тому же опыта работы с Unity и С# у мне не было и нет.
Меня в общем то в Qt устраивает все. Кроме лицензии пожалуй. LGPL с одной стороны позволяет использовать софт в коммерчеких целях, но там какие-то сложные моменты, типа того что нельзя линковать библиотеки статически, а IOS зарпещеат линковаться динамически, и еще много тонкостей и органичений.
По поводу быстрого рендеринга: я использую непосредственно OpenGL/ES, объединяю всю похожую геометрию в группы(batch). Все символы на карте также рисуются за 1 вызов. Линии тесселируются на CPU, а сглаживаются во фрагментном шейдере. В итоге производительность раза в 3 выше чем в OpenCPN при значительно более качественной графике. Навряд ли можно сделать быстрее, чем с помощью непосредственно графического API. https://www.youtube.com/watch?v=msDhjk1dndk
ignat9920.01.2022 в 19:37
Производительсность не может быть выше в 3 раза. Возможно у вас был кастрированный OpenCPN на сравнении.
И там и там OpenGL. Если говорить что OpenCPN медленние, то надо точно указывать со ссылкой на профаил в каких именно операциях он теряет. Может это просто свойство той платформы\железа на котором вы тестовый запуск делали.
Кроссплатформенность именно из за применения wxWidgets достигается. Причём найтивная. Потому что несколько разработчиков в различное время по сути сделали wxWidgets аналоги под основые 4 операционные системы. Кроме того, он есть на почти всех языках программирования в виде вызываемых библиотек.
Возможно в вашем проекте просто не используются сложные диалоги и формы, нет интернационализации и т.д.
Из вашего видео видно, что вы сравниваете аппаратное ускорение с симулятором софтварным. Вообщем очень жаль, что вы даже этого и не заметили.
К слову на хороших современных аппаратных ускорителях можно смотреть 3D сцену одновременно с нескольких точек зрения.
Моё мнение, что если собрать правильно OpenCPN c поддержкой ускорителя, то разница в скорости будет связана только с отрисковкой дашборда, которого у вас на экране нет. То что стоит сбоку от карты – это отдельная аппаратная область вывода.
Тут статья про OpenCPN. Давайте больше не отклонятся от заявленной темы. OpenCPN это не про отрисовку карты, а про прокладку пути, редактирование списков и подключение в одном дашборте кучи инструментов. Познакомтесь с руководством по OpenCPN.
И я понимаю вас, что очень сложно без привычки разбираться в чужом коде, что гораздо проще написать своё. Но когда написанное с нуля достигнет такого же функционала как OpenCPN оно будет уже никому не нужно, так изначально ориентировано на OpenGL, который был сделан просто для потдержки VRML, а не для отрисовки реалистичных сцен. Для которых уже используют CUDA вычисления и более современные технологии.
CUDA это не совсем чистый СИ.
А если вам нужна скорость настоящая надо смотреть в сторону современных ПЛИС (FPGA).
black_list_man20.01.2022 в 21:02
С чего Вы взяли что в OpenCPN на видео отключего ускорение OpenGL? Оно включего по умолначни, в меню-> отображение -> дополнительно-> использовать ускорение OpenGL. Сравнение вполне коррентное. OpenCPN 5.2.4 из официального сайта, я его не собирал самостоятельно. Без ускорения было бы в районе 5 FPS (я сейчас попробовал отключить). На видео видно что в некорых сценах FPS падает ниже 60, судя по плавности, счетчик почему-то не работает, хотя включен в опциях (карта GTX 1060). В моем рендере FPS почти никогда не опускатеся ниже 180 даже в самых нагруженых сценах, в среднем больше 200. Настройки парамтеров отображения карты оналогичны. Сравнивал производительность на разных устойствах. Отошение примерно такое, как я сказал.
А как функционал влияет на fps? Он есть, где-то там. Но не включен же постоянно, т.е. не влияет ни на время формирование кадра ни на отрисовку. Я не думаю что дашборд вообще может как-то сущетвенно влияеть на производительность. По сравнению с картой, сотоящей из миллиона полигонов, сотен тысяч вершин, и тысячи спрайтов, одновременно находящихся на экране это несущественно. Ровно как и наличие диалогов с формами. Как факт их наличия может оказывать влияние на производительность, особенно в части отрисовки карты? При сравнении я стараюсь создавать одинаковые условия, ни там ни там не открыти ни диалоги, ни дашборды. И кстати, сайдбар сбоку: что значит отдельная область вывода? Он отрисовывется в том же контексте, что и вся карта. QML сначала передает контекст мне, я рисую все что нужно – а потом, сверху уже рисуется весь интерфейс. Но я не думаю что он “съедает” больше 1 FPS.
Разница в производительности обосновата как минимум тем, что OpenCPN не объединяет похожую геометрию в batch. Тысячи объектов на экране = равно тысячи вызовов отрисовки. Batching – это самый очевидный способ оптимизации рендера. Использует glBegin – glEnd вместо, того чтобы рисовать геометрию из вершинного буфура (VBO). Совершенно не задействуется многопоточность при подготовке кадра. Вот она и трехкратная разница в производительности . Я в коде OpenCPN где-то на протяжении года ковырялся и вполне себе разобрался. Изначально именно на его базе делался весь функционал, для нужд лаборатории. На видео 2018 года еще осталась та самая версия на базе OCPN.
https://www.youtube.com/watch?v=SwgmZaP3HGU
ignat9921.01.2022 в 11:00
У вас отключена аппаратня OpenGL для OpenCPN. Разбирайтесь сами.
По поводу своего спама пишите свою статью.
OpenCPN это работа с базой данных, форматами карт, внешними устройствами и источниками данных. Так же связь с другими яхтами и т.д.
Прочитайте вначале мануал прежде чем тут еще раз что либо говорить.
OpenCPN Books/Manuals
black_list_man21.01.2022 в 01:37
И кстати, я до сих пор не могу понять причем тут CUDA? Точно ли ту СUDA, Вы имеет в виде, что SDK от Nvidia? CUDA – во-первых работает только на картах Nvidia, во-вторых, предназначена для выполнения параллельных вычислений общего характера и не имеет вообще никакого отношения к рендеру. Это тоже самое что вычислительный шейдер. Или OpenCL. Вычислительный шейдеры давно есть в современном OpenGL/ES, как Вы предлагаете их использовать в данной задаче? Разве можно CUDA вообще противопоставлять графическим API, типа OpenGL?
ignat9921.01.2022 в 11:01
Запишитесь, на курсы компьютерной грамотности. Задайте там вопрос про вокселы.
OpenCPN это в первую очередь не про отрисовку сцены, а про прокладку курса и про реагирования на события и данные подгружаемые в буферы в реальном времени. Читайте вначале мануал OpenCPN Books/Manuals
Ваша поделка близко к этим задачам пока не подошла и не подойдёт, если у вас в команде будет единственный программист, который вместо работы занимается троллингом.
black_list_man21.01.2022 в 11:47
Пержде чем поучать удосужтесь ответить хотя бы на один из вопросов. Я еще раз справшиваю, на каком основании Вы утверждаете что в моей версии OpenCPN отключена поддержка OpenGL? Я Вам дал развернутый ответ о том, где я взал эту версию, показал пункт меню, в котором отчетливо видно, что OpenGL включен. Его можно отключить и заметить разницу. А Вы почему-то продолжаете утверждать что это не так. Почему? В мануле, который Вы мне зачем-то даете, и который я в свое время прочитал вдоль и поперек, нет ответа ни на один из вопросов.
Что значит спам? Я оставил один единсвтенный комментарий под этой статьей, в котором рассказал своем опыте работы с OCPN и сборки под Android. Дальнейший диалог Вы развиваете сами. Сами же затронули вопрос о “быстром рендере” и производительности. И эта ветка диалога именно об этом.
Что касается грамотности, я уверен что это Вам нужно внимательно изучить хотя бы терминилогию, и понять что же из себя предсвляет CUDA и в каких отношениях она находится с графическими API. Я не уверен что вообще могу Вас понять. Намешали все вместе, карты, воксели, CUDA, OpenGL. Как это связано? Скажите честно, Вы имели опыт работы с OpenGL и в полной мере понимаете о чем идет речь?
Моя “поделка” (почему в таком унизительной тоне?) выполняет ровно те задачи, для которых создавалсь и обладает ровно тем функционалом, который от нее требуется. Почему одна должна повторять функционал OpenCPN? Это два разных софта, котоые я сравниваю лишь в части производительности рендера.
Не хотите продолжать диалог – не продолждайте более. Я лично не привык оставлять обвинения в мой адрес неотвечеными.
ignat9921.01.2022 в 12:26
Сложно говорить с технически безграмотным в области компьютерных вычислений человеком.
Вам никто ничего не обязан. Вы официально тролль и это крайнее сообщение вам.
Вам сейчас не более 29 лет и да, вы IT самозванец без опыта. Это вам мой фидбак. Хотели получить. Получите и распишитесь. Джуниором я бы вас не взял, и практикантом тоже. И стажёром. И даже учеником за доплату.
ignat9920.01.2022 в 17:50
wxWidgets/glcanvas.h at master · bdbcat/wxWidgets (github.com)
Вот этот файл, похоже, хватает ветка android OpenCPN. Как я понял этот файл цепляет Windows библиотеки. Не уверен что это правильно в контексте Android.
ignat9920.01.2022 в 18:09
universal binary for macOS · Issue #2486 · OpenCPN/OpenCPN (github.com)
Вот тут обсуждение, товарищи не могут даже отключить потдержку OpenGL, хотя ранее все хорошо работало в этом плане (в плане отключения лишнего).
ignat9924.01.2022 в 15:59
Для того чтоб OpenGL заработал в Android, нужно собрать соответствующие библиотеки под ARM.
GL/gl.h, Qt5 and arm: FTBFS (debian.org)
Ответы:
Re: GL/gl.h, Qt5 and arm: FTBFS (debian.org)
Re: GL/gl.h, Qt5 and arm: FTBFS (debian.org)
И это не столько проблема закрытых драйверов, сколько проблема закрытых Даташитов. Потому что там информация о багах внутри реализации графических ядер и их встраивания в SoC. Корпорации на момент выпуска устройства скрывают косяки в изделии, даже от большинства своих сотрудников (по крайней мере младших чем 4 ранг и работающих в другой области кода).
А косяки производителя, закрытые драйвера + особенности и тайны встроенного гипервизора создают поистине гремучую смесь. И 5 лет назад приходилось выбирать Qt5 или аппаратный OpenGL …