To get to know our potential clients, you need their analysis
(I am for a creative approach to the task, otherwise it is too simple. As well as the idea to take everything ready. Be sure to add your own perspective based on your own experience.)
We have a list of airports in major cities. There may be our clients from these cities who will undergo remote training courses before arriving in Spain.
We have an Artificial Intelligence network that regularly analyzes all the statements of each of our students. We are developing a REST API service in Python that will analyze the received data and identify the demand for new training courses among residents of different age groups in different cities through advertising channels.
Let’s implement the following handlers in the service:
- a. POST /upload CSV file in this format: https://gist.githubusercontent.com/stepan-passnfly/8997fbf25ae87966e8919dc7803716bc/raw/37c07818c8498ae3d587199961233aada88ed743/airports.csv (define table and save DDL query)
- b. PUT /create an entry in the previous table.
- c. PATCH /update an entry in the previous table.
- d. DELETE /delete an entry in the previous table.
- e.
OPTIONS /:entity[/:id]Gets a list of methods available at the given URI. The server should respond with 200 OK with an additional Allow header: GET, POST, ... - f. GET /create – create and returns a link with confirmation
- g. GET /update – returns a link with confirmation
- h. GET /delete – sets a flag in the database to delete this record.
POST /imports
Добавляет новую выгрузку с данными;GET /imports/$import_id/citizens
Возвращает жителей указанной выгрузки;PATCH /imports/$import_id/citizens/$citizen_id
Изменяет информацию о жителе (и его родственниках и друзьях) в указанной выгрузке;GET /imports/$import_id/citizens/birthdays
Вычисляет число курсов, которое приобретет каждый житель выгрузки своим родственникам\друзьям (первого порядка), сгруппированное по каналам рекламы;GET /imports/$import_id/towns/stat/percentile/age
Вычисляет 50-й, 75-й и 99-й перцентили возрастов (полных лет) жителей по городам в указанной выборке.
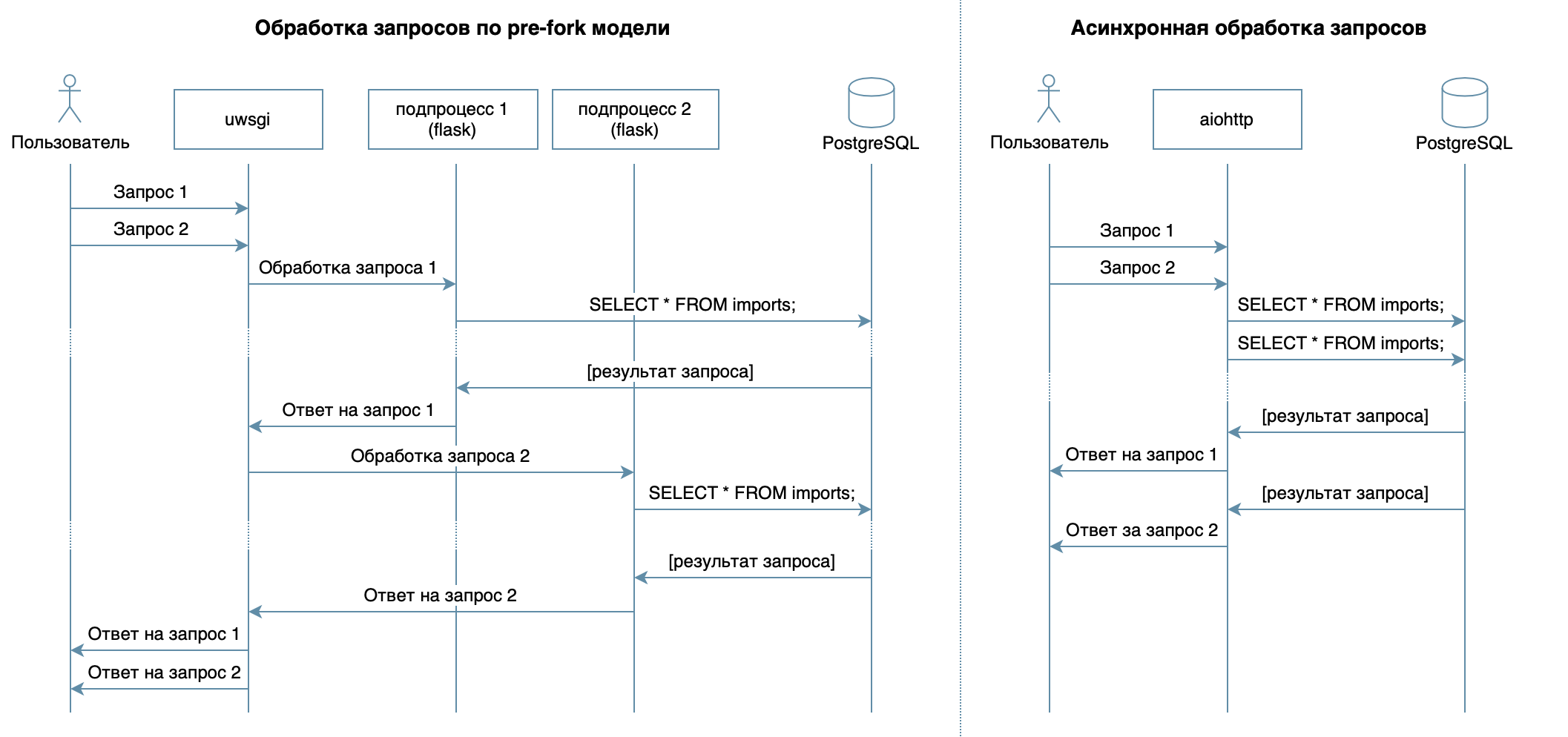
Alternative frameworks
List of the best frameworks:
https://www.techempower.com/benchmarks/#section=data-r19&hw=ph&test=fortune&l=zijzen-1r
Explored alternatives:
asyncpg — A fast PostgreSQL Database Client Library for Python/asyncio (1 000 000 line per second)
asyncpgsa — A python library wrapper around asyncpg for use with SQLAlchemy
aiohttp — as a library for writing an asynchronous framework service, since it generally works 2 times? faster.
aiohttp-spec — binds aiohttp handlers and schemas for data validation. As a bonus, it turned out to generate documentation in the format Swagger and display it in графическом интерфейсе.
Ancient technologies of RabbitMQ
aioamqp, a pure-Python AMQP 0-9-1 library using asyncio (source code, docs)
celery – alternative asynchronous library under Python
The tools we have chosen
flask-restx — It is a flask framework with the ability to automatically generate documentation using Swagger.
Apache Kafka — Is an open-source distributed event streaming platform
PostgreSQL – database
SQLAlchemy allows you to decompose complex queries into parts, reuse them, generate queries with a dynamic set of fields (for example, a PATCH handler allows partial updating of an inhabitant with arbitrary fields or ElasticSearch reading) and focus directly on the business logic.
Alembic is a lightweight database migration tool for usage with the SQLAlchemy Database Toolkit for Python.
1:33:49 – How to write and test database migrations with Alembic – Alexander Vasin.
Docker (composer and swarm) or Kubernetes (k8s)
Ansible — For deployment, it allows declaratively describing the desired state of the server and its services, works via ssh and does not require special software.
pylint and pytest and unittest
Profilers
PyCharm
python -m cProfile -o pick.prof -s tottime app.py — Python only profiler.
snakeviz pick.prof — web visualizer.
python3 -m vmprof app.py – profiles C functions.
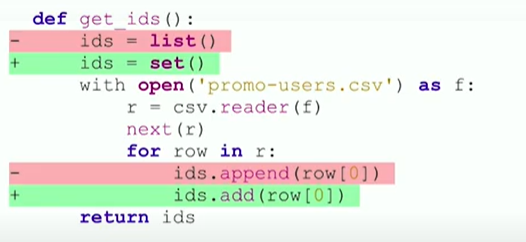
Threadpool – for reading files asynchronously on Linux.
Analysis of program memory consumption:
import tracemalloc
tracemalloc.start()
tracemalloc.take_snapshot()
mprof – graph of memory consumption over time.
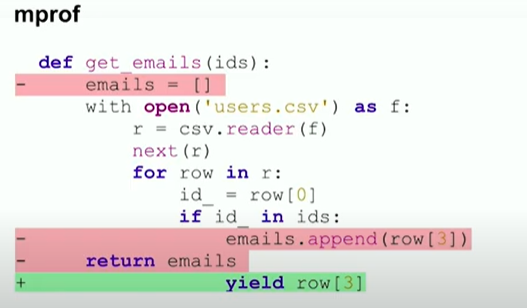
Further optimization is to extract a fixed part from the file each time. For example 1024 lines.
uvloop — To connect data loops over the network with PostgreSQL.
Postman — generating API requests.
Installation node
wget http://nodejs.org/dist/latest/node-v15.2.0-linux-x64.tar.gz
tar -xzf node-v15.2.0-linux-x64.tar.gz
ls mv node-v15.2.0-linux-x64 15.2.0
ln -s 15.2.0/ current
export PATH=”/home/ubuntu/.nodes/current/bin:$PATH”
rm node-v15.2.0-linux-x64.tar.gz
node –version
npm install
How to activate Swagger
sudo apt install python3-pip
sudo pip3 install -e .[dev]
sudo env “PATH=/home/ubuntu/.nodes/current/bin:$PATH” inv assets
Loading data into PostgreSQL
http://www.jennifergd.com/post/7/
sudo /etc/init.d/postgresql start
psql -U postgres -h localhost insikt
CREATE TABLE cities (id SERIAL PRIMARY KEY, name VARCHAR(256), city VARCHAR(50), country VARCHAR(50), iata VARCHAR(10), icao VARCHAR(10), latitude FLOAT, longitude FLOAT, altitude FLOAT, timezone FLOAT, dst VARCHAR(10), tz VARCHAR(50), type VARCHAR(50), source VARCHAR(50));
\copy cities(name, city, country, iata, icao, latitude, longitude, altitude, timezone, dst, tz, type, source) FROM 'airports.csv' DELIMITERS ',' CSV HEADER;
SELECT * FROM cities;
PostGIS
sudo apt-get install postgis
psql -U postgres -h localhost insikt
CREATE EXTENSION postgis;CREATE TABLE citiesgeo ( point_id SERIAL PRIMARY KEY, location VARCHAR(30), latitude FLOAT, longitude FLOAT, geo geometry(POINT) );
cities.csv
location, latitude, longitude
San Francisco, 37.773972, -122.43129
Seattle, 47.608013, -122.335167
Sacramento, 38.575764, -121.478851
Oakland, 37.804363, -122.271111
Los Angeles, 34.052235, -118.243683
Alameda, 37.7652, -122.2416
In PostgreSQL shell:
=# \copy citiesgeo(location, latitude, longitude) FROM ‘cities.csv’ DELIMITERS ‘,’ CSV HEADER;
COPY 6
=# SELECT * FROM citiesgeo;
point_id | location | latitude | longitude | geo
———-+—————+———–+————-+—–
1 | San Francisco | 37.773972 | -122.43129 |
2 | Seattle | 47.608013 | -122.335167 |
3 | Sacramento | 38.575764 | -121.478851 |
4 | Oakland | 37.804363 | -122.271111 |
5 | Los Angeles | 34.052235 | -118.243683 |
6 | Alameda | 37.7652 | -122.2416 |
(6 rows)
https://postgis.net/docs/ST_Point.html
=# UPDATE citiesgeo
SET geo = ST_Point(longitude, latitude);
UPDATE 6=# SELECT * FROM citiesgeo;
point_id | location | latitude | longitude | geo
———-+—————+———–+————-+——————————————–
1 | San Francisco | 37.773972 | -122.43129 | 0101000000E1455F419A9B5EC08602B68311E34240
2 | Seattle | 47.608013 | -122.335167 | 0101000000B3EC496073955EC07C45B75ED3CD4740
3 | Sacramento | 38.575764 | -121.478851 | 01010000000B2AAA7EA55E5EC0691B7FA2B2494340
4 | Oakland | 37.804363 | -122.271111 | 01010000007FA5F3E159915EC0658EE55DF5E64240
5 | Los Angeles | 34.052235 | -118.243683 | 0101000000D6E59480988F5DC0715AF0A2AF064140
6 | Alameda | 37.7652 | -122.2416 | 0101000000ACADD85F768F5EC01973D712F2E14240
(6 rows)
We make position in WGS84 format.
=# INSERT INTO citiesgeo (location, latitude, longitude, geo)
VALUES (‘San Rafael’, 37.9735, -122.5311, ST_Point(-122.5311, 37.9735));
INSERT 0 1=# INSERT INTO citiesgeo (location, latitude, longitude, geo)
VALUES (‘San Rafael’, 37.9735, -122.5311, ST_Point(-122.5311, 37.9735));
INSERT 0 1
https://postgis.net/docs/ST_DistanceSphere.html
=# SELECT * FROM citiesgeo WHERE ST_DistanceSphere(geo,(SELECT geo FROM citiesgeo WHERE location = ‘San Francisco’
)) < 83000;
point_id | location | latitude | longitude | geo
———-+—————+———–+————-+——————————————–
1 | San Francisco | 37.773972 | -122.43129 | 0101000000E1455F419A9B5EC08602B68311E34240
4 | Oakland | 37.804363 | -122.271111 | 01010000007FA5F3E159915EC0658EE55DF5E64240
6 | Alameda | 37.7652 | -122.2416 | 0101000000ACADD85F768F5EC01973D712F2E14240
7 | San Bruno | 37.6305 | -122.4111 | 0101000000AED85F764F9A5EC062105839B4D04240
8 | San Rafael | 37.9735 | -122.5311 | 0101000000F5B9DA8AFDA15EC0F853E3A59BFC4240
(5 rows)
ALTER TABLE cities ADD COLUMN geo geometry(POINT);
-# SET geo = ST_Point(longitude, latitude);
UPDATE 7698
Launching the application in test mode
sudo python3 setup.py install
screen -dmS abc
screen -r abc
./app.py
Ctr-a d
docker-compose.yml – this is an outdated part that we are changing to a more modern one
Some companies work using outdated technologies due to the fact that they hired specialists with limited experience or, more precisely, ordered their systems from outsourcers (for example, from Ukraine). Below is an example of such a deprecated docker-composer.yml MySQL + RabbitMQ configuration.
version: ‘3.4’
services:
database:
image: mysql:5.7.21
ports:
– 3306:3306
environment:
– MYSQL_ROOT_PASSWORD=test
– MYSQL_USER=test
– MYSQL_PASSWORD=test
– MYSQL_DATABASE=mysqltest
volumes:
# – data02:/var/lib/mysql
– /home/ubuntu/opt/docker-volumes/mysql:/var/lib/mysql
networks:
default:
ipv4_address: 172.18.0.4
# rabbitmq:
# image: rabbitmq:3.6.12-management
# hostname: rabbitmq
# volumes:
# – /home/ubuntu/opt/docker-volumes/rabbitmq:/var/lib/rabbitmq
# environment:
# – RABBITMQ_DEFAULT_PASS=admin
# – RABBITMQ_DEFAULT_USER=admin
# – RABBITMQ_DEFAULT_VHOST=/
# ports:
# – 5672:5672
# – 15672:15672
# networks:
# default:
# ipv4_address: 172.18.0.3
Apache kafka and PostgreSQL
![]() This is how kafka containers look like in Docker. Below are the installation instructions:
This is how kafka containers look like in Docker. Below are the installation instructions:
https://docs.confluent.io/current/quickstart/ce-docker-quickstart.html
Our server:
Then we test and create an asynchronous client.

Doing a little refactoring
https://github.com/Ignat99/restx2020
Since we have accumulated many layers and functions. For example API, ORM, business logic, Model, database schema, then for ease of maintenance we will distribute these functions in different modules. Everything could be left in one file. But since we have attached asynchronous processing and work with the Kafka Broker in dedicated threads that are synchronized through Kafka, it is better to separate the modules.

SonarQube with local PostgreSQL
https://gist.github.com/RawToast/feab6b36d2592554d071
sudo psql -U postgres postgres
CREATE DATABASE sonar;
CREATE USER sonar WITH PASSWORD ‘verysecret’;
GRANT ALL PRIVILEGES ON DATABASE sonar TO sonar;
Install SonarQube
cd /opt
sudo wget https://binaries.sonarsource.com/CommercialDistribution/sonarqube-developer/sonarqube-developer-8.5.1.38104.zip
sudo unzip sonarqube-developer-8.5.1.38104.zip
sudo mv sonarqube-8.5.1.38104/ sonarqube
or
git clone https://github.com/SonarSource/sonarqube
cd sonarqube/
./gradlew build
or
sudo docker run -d –name sonarqube -p 9000:9000 -e SONARQUBE_JDBC_USERNAME=sonar
-e SONARQUBE_JDBC_PASSWORD=verysecret -e SONARQUBE_JDBC_URL=jdbc:postgresql://localhost:5432/sonar –net mynet sonarqube:7.5-community
sudo docker exec -it -u root sonarqube /bin/bash
sudo sysctl -w vm.max_map_count=262144
cd /opt/sonarqube
sh bin/linux-x86-64/sonar.sh start
netstat -tap
tcp6 0 0 [::]:9000 [::]:* LISTEN 5819/java
Tests
https://github.com/Ignat99/a_proxy
https://github.com/Ignat99/JSON_Test/blob/master/test_json.py
sudo pip3 install nose coverage nosexcover pylint
sudo pip3 install pylint_flask_sqlalchemy
sudo pip3 install pylint-flask
pylint –generate-rcfile > pylintrc
pylint passnfly/
To see duplicate lines and test coverage in SonarQube:
./coverage.sh
pytest -s –junitxml=pytests.xml –cov-report xml –cov-report term –cov-branch –cov=passnfly tests/
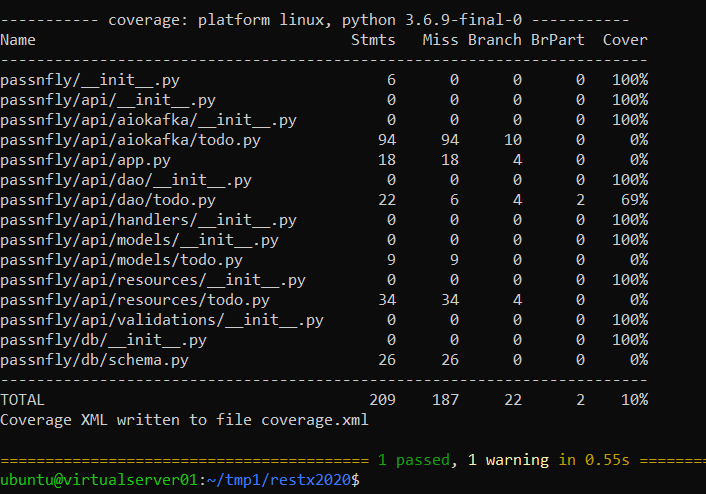
Sonar-scaner
../sonar-scanner/bin/sonar-scanner -Dsonar.projectKey=passnfly1 -Dsonar.sources=. -Dsonar.host.url=http://75.126.254.59:9000 -Dsonar.login=cf56501e7eca2051eb7510911ceec0b4e8b1cf66
Web interface of SonarQube
http://75.126.254.59:9000/dashboard?id=passnfly1
Python thread support for accessing asynchronous processes
https://github.com/Ignat99/restx2020/blob/main/passnfly/api/aiokafka/todo.py
In this part of our backend, a special class of Threads in debug mode is implemented, which allows stopping the child from the parent thread based on its name.
As the identifier of the asynchronous process, we use the hash that we generated for the partition of this topic in Kafka.
https://github.com/Ignat99/restx2020/blob/main/passnfly/api/aiokafka/todo.py#L111
All this gives great flexibility up to managing the entire banned by using the REST API from one of the threads.
Here we make sure that one thread is launched per task.
https://github.com/Ignat99/restx2020/blob/main/passnfly/api/aiokafka/todo.py#L122
The duration of our stream can be up to 2 weeks and is limited by the Kafka settings. Every 2 weeks, the oldest data in our partition is released. If our service did not manage to process the data in 2 weeks (it can be reconfigured in Kafka), then this data should be stored in longer storages, such as S3 / Hadoop. There is an old driver for RabbitMQ, but it doesn’t work well.
https://docs.confluent.io/clients-confluent-kafka-python/current/index.html
https://kafka-python.readthedocs.io/en/master/usage.html
Flask RESTX API testing
https://github.com/Ignat99/restx2020/tree/main/tests/api
https://riptutorial.com/flask/example/5622/testing-a-json-api-implemented-in-flask
https://flask.palletsprojects.com/en/1.1.x/testing/
Kafka – Idempotent Producer and Consumer
Как Kafka стала былью / Блог компании Tinkoff / Хабр (habr.com)
Will help client.id for Producer and Consumer. It is best to use a combination of the application name and, for example, the topic name as the client.id value.
Kafka Producer has the acks parameter that allows you to configure after how many acknowledge the cluster leader should consider the message as successfully written. This parameter can take the following values:
0 – acknowledge will not be counted.
1 – default parameter, acknowledge only from 1 replica is required.
−1 – acknowledge from all synchronized replicas are required (cluster setting min.insync.replicas).
From the listed values, it can be seen that acks equal to -1 gives the strongest guarantees that the message will not be lost.
As we all know, distributed systems are unreliable. To protect against transient faults, Kafka Producer provides a retries parameter that allows you to set the number of retry attempts during delivery.timeout.ms. Since the retries parameter has a default value of Integer.MAX_VALUE (2147483647), the number of retransmissions of a message can be adjusted by changing only delivery.timeout.ms. In some cases, this will be more convenient due to the fact that Producer will make the maximum number of re-submissions within the specified time interval. We set the interval to 30 seconds.
Kafka — Idempotent Producer And Consumer | by Sheshnath Kumar | Medium
In the simplest case, for this on the Producer, you need to set the enable.idempotence parameter to true. Idempotency guarantees that only one message is written to a specific partition of one topic. The precondition for enabling idempotency is the values acks = all, retry> 0, max.in.flight.requests.per.connection ≤ 5. If these parameters are not specified by the developer, the above values will be automatically set.
Producer:
- acks = all
- retries > 0
- enable.idempotence = true
- max.in.flight.requests.per.connection ≤ 5 (1 — для упорядоченной отправки)
- transactional.id = ${application-name}-${hostname}
Consumer:
- isolation.level = read_committed
KIP-98 perf testing – Google Sheets
For 1K messages and transactions lasting 100ms, the producer bandwidth is reduced by:
3% compared to its performance when it is configured for at least once in-order delivery (acks = all, max.in.flight.requests.per.connection = 1),
by 20% compared to its operation when configured to at most once without respecting message order (acks = 1, max.in.flight.requests.per.connection = 5) is used by default.
Exactly Once Delivery and Transactional Messaging in Kafka – Google Docs
KIP-129: Streams Exactly-Once Semantics – Apache Kafka – Apache Software Foundation
Access control is configured on your cluster.
transactional.id.expiration.ms, which is configured on the Kafka cluster and has a default value of 7 days.
Confluent’s Python Client for Apache Kafka
Install
git clone https://github.com/edenhill/librdkafka
cd librdkafka/
git checkout v1.6.0-RC1
./configure
make
sudo make install
cd ../confluent-kafka-python/
git checkout v1.6.0-PRE4
python3 setup.py build
sudo python3 setup.py install
….
Finished processing dependencies for confluent-kafka==1.6.0
Pull request
Clone repo to my github.com
git clone Ignat99/confluent-kafka-python: Confluent’s Kafka Python Client (github.com)
cd confluent-kafka-python/
git remote add upstream git://github.com/confluentinc/confluent-kafka-python
git fetch upstream
git checkout v1.6.0-PRE4
python3 setup.py build
sudo python3 setup.py install
…
Finished processing dependencies for confluent-kafka==1.6.0
git checkout -b enable_idempotence
This is where we make a change to the library and later return the pull request.
git push origin enable_idempotence