My approach to Agentic Infrastructure shifts the paradigm from mass-scale indiscriminate scraping—which currently fuels ongoing DMCA litigation—to a deterministic, physics-informed retrieval and reasoning architecture. By moving the GTI Agentic team toward a graph-based, target-specific data acquisition model, we can transform Google Cloud’s AI from a ‘content-aggregating’ liability into a ‘scientifically-grounded’ asset. This architectural shift serves as the primary technical defense against copyright infringement claims, demonstrating a systemic commitment to high-precision, curated data governance rather than uncontrolled mass ingestion.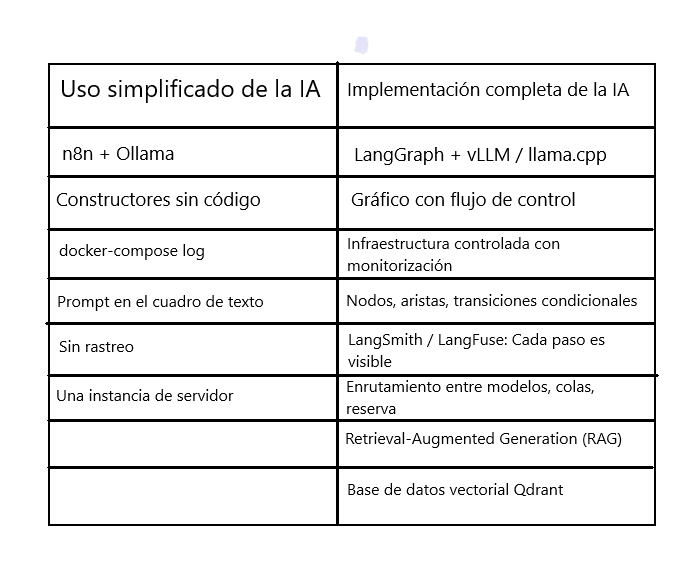
La arquitectura en este caso puede imaginarse como una cadena simple: el usuario hace clic en el punto final REST en Spring Boot, la solicitud va a Spring AI, que la vectoriza (modelo Embedding) y va a Qdrant (base de datos vectorial) para obtener los fragmentos de texto relevantes, y solo entonces los combina en una solicitud para el modelo local a través de Ollama. Si en LangFuse no puedes ver cada paso del razonamiento de un agente, no estás manejando el sistema, estás jugando a la lotería.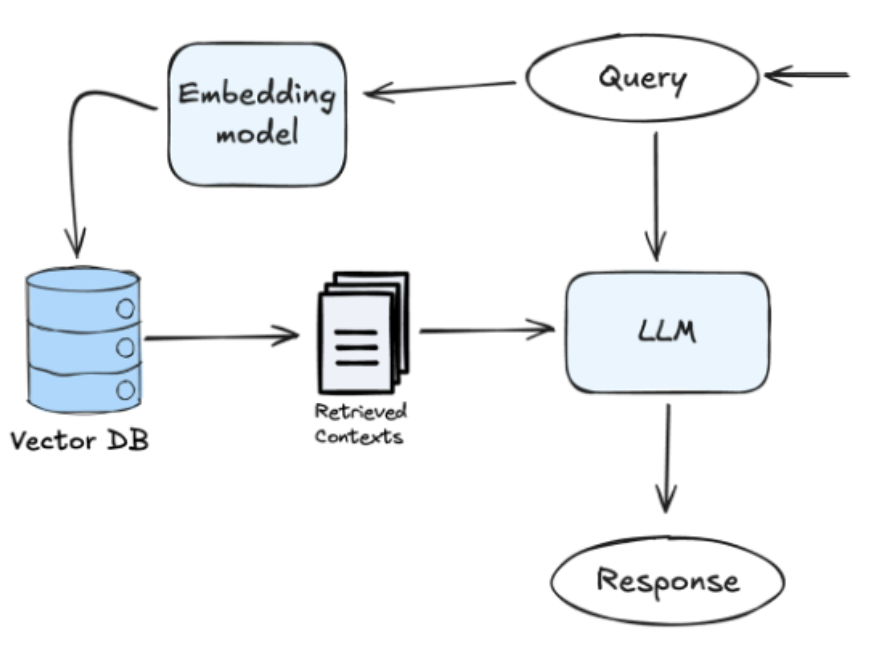
Para RAG, necesitamos un almacén de vectores independiente para guardar las incrustaciones de documentos. Qdrant es perfecto para esto: ofrece búsqueda rápida mediante redes neuronales artificiales, admite gRPC y HTTP, y se integra bien con Spring AI. Para evitar la instalación manual, ejecutaremos Qdrant en un contenedor Docker.
- Reenviamos los puertos 6333 (HTTP) y 6334 (gRPC) al host; Spring AI se comunica con Qdrant a través de gRPC por defecto.
- Habilitamos la clave API a través de QDRANT__SERVICE__API_KEY para que el almacenamiento de vectores no sea fácilmente accesible desde el exterior.
- Montamos ./qdrant_storage en el directorio de almacenamiento interno de Qdrant para que las colecciones y las incrustaciones no desaparezcan después de reiniciar un contenedor.
- Ahora veamos las dependencias necesarias para una aplicación Java/Kotlin Spring Boot. Agregaremos Spring AI y los starters para Ollama y Qdrant al proyecto. Para Gradle (build.gradle.kts)
- Crearemos un servicio RAG para ello, utilizando clientes prefabricados para Qdrant y Ollama, que deberían responder preguntas basadas en datos de la base de datos vectorial de Qdrant.
- Dado que Qdrant aún no dispone de datos, necesitamos añadir un servicio de indexación y almacenamiento de documentos, que además se puede integrar fácilmente mediante Spring AI.
CosyVoice LLM
CosyVoice3 es uno de los mejores modelos de síntesis de voz de código abierto disponibles actualmente, especialmente para el ruso. Sin embargo, tiene un problema: el componente PyTorch LLM se ejecuta lentamente en GPU de gama baja como la T4. El factor de tiempo real (RTF) ronda el 1,17, lo que significa que sintetizar un segundo de audio requiere más de un segundo de tiempo real.
CosyVoice LLM no es un modelo de lenguaje común.
CosyVoice3 utiliza LLM (basado en Qwen2.5-0.5B) para generar tokens de voz. Sin embargo, no es un modelo de lenguaje estándar: tiene dos capas y dos conjuntos de incrustaciones:
- Incrustaciones de texto (embed_tokens): el vocabulario estándar de Qwen, ~151.936 tokens.
- Incrustaciones de voz (speech_embedding): 6.561 tokens de audio.
- Capa de voz (llm_decoder): una capa de salida independiente para los tokens de voz.
llama.cpp desconoce esta arquitectura. Espera un modelo estándar con un vocabulario y una capa lm_head.
Existe una bifurcación de FastCosyVoice con soporte para TensorRT-LLM for RTX 3090 and RTX 5060ti.
MCP-servers
https://github.com/modelcontextprotocol/kotlin-sdk
https://github.com/langchain-ai/langgraph
https://github.com/vllm-project/vllm
https://github.com/Ekstrem/Communication-modeling
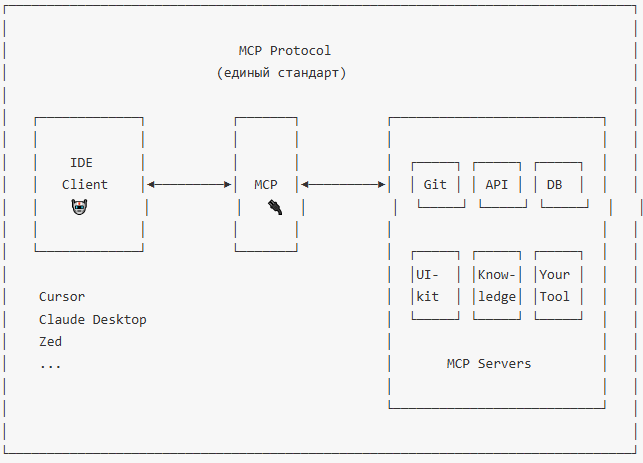
El Protocolo de Contexto del Modelo es un protocolo de comunicación entre un asistente de IA y fuentes de datos externas, desarrollado por Anthropic. Este protocolo está diseñado para resolver el problema de las indicaciones extensas y la gran cantidad de instrucciones de texto en LLM (por ejemplo, los mismos archivos AGENTS.md o .cursor/rules/**).
GPT para I+D
Amazon Web Services (AWS)
En 2018, ensamblamos esta arquitectura nosotros mismos a partir de componentes individuales.
Ahora esto se puede hacer dentro del servicio de Amazon.
AWS MSK (Kaffka), EMR ( Apache Spark/Storm, Hadoop, Flink, and Hive), SQS (Amazon Simple Queue Service), Amazon OpenSearch Service. Conocimientos básicos de seguridad en AWS (IAM, MFA, WAF, CloudTrail, KMS, TLS).
Lo que resulta especialmente importante es la posibilidad de ahorrar tiempo de facturación gracias a AWS Lambda.
El mejor resultado se obtiene si el cuello de botella se reescribe en lenguajes compilados (Go, Rust).
IRC bouncer (BNC)
Un proxy BNC (intermediario de IRC) es un servidor proxy especializado que actúa como intermediario entre tu cliente IRC y la red IRC. Te mantiene conectado permanentemente a IRC, lo que te permite recibir el historial de mensajes incluso sin conexión, ocultar tu dirección IP real por seguridad y sincronizar conversaciones en varios dispositivos.
Zenroom es programable en Zencode, un lenguaje sin código similar al inglés.
Hermes-agent Un intermediario del lado del servidor para configurar redes neuronales y corregir el código fuente.